🔥 Load Test LiteLLM
How to run a locust load test on LiteLLM Proxy
- Add
fake-openai-endpointto your proxy config.yaml and start your litellm proxy litellm provides a free hostedfake-openai-endpointyou can load test against
model_list:
- model_name: fake-openai-endpoint
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
pip install locustCreate a file called
locustfile.pyon your local machine. Copy the contents from the litellm load test located hereStart locust Run
locustin the same directory as yourlocustfile.pyfrom step 2locustOutput on terminal
[2024-03-15 07:19:58,893] Starting web interface at http://0.0.0.0:8089
[2024-03-15 07:19:58,898] Starting Locust 2.24.0Run Load test on locust
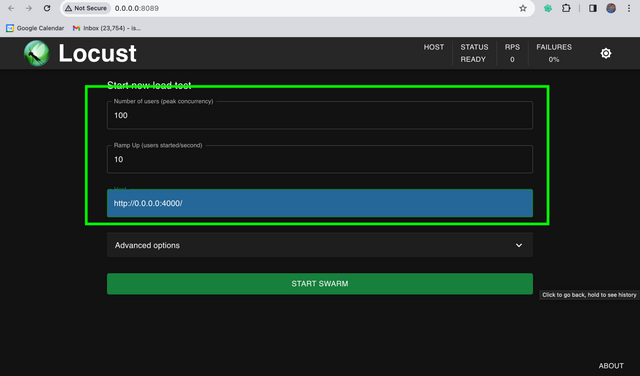
Head to the locust UI on http://0.0.0.0:8089
Set Users=100, Ramp Up Users=10, Host=Base URL of your LiteLLM Proxy
Expected Results
Expect to see the following response times for
/health/readinessMedian → /health/readiness is150msAvg → /health/readiness is
219ms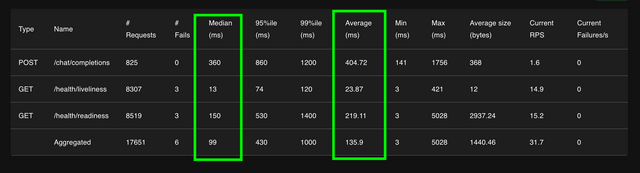
Load Test LiteLLM Proxy - 1500+ req/s
1500+ concurrent requests/s
LiteLLM proxy has been load tested to handle 1500+ concurrent req/s
import time, asyncio
from openai import AsyncOpenAI, AsyncAzureOpenAI
import uuid
import traceback
# base_url - litellm proxy endpoint
# api_key - litellm proxy api-key, is created proxy with auth
litellm_client = AsyncOpenAI(base_url="http://0.0.0.0:4000", api_key="sk-1234")
async def litellm_completion():
# Your existing code for litellm_completion goes here
try:
response = await litellm_client.chat.completions.create(
model="azure-gpt-3.5",
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
)
print(response)
return response
except Exception as e:
# If there's an exception, log the error message
with open("error_log.txt", "a") as error_log:
error_log.write(f"Error during completion: {str(e)}\n")
pass
async def main():
for i in range(1):
start = time.time()
n = 1500 # Number of concurrent tasks
tasks = [litellm_completion() for _ in range(n)]
chat_completions = await asyncio.gather(*tasks)
successful_completions = [c for c in chat_completions if c is not None]
# Write errors to error_log.txt
with open("error_log.txt", "a") as error_log:
for completion in chat_completions:
if isinstance(completion, str):
error_log.write(completion + "\n")
print(n, time.time() - start, len(successful_completions))
time.sleep(10)
if __name__ == "__main__":
# Blank out contents of error_log.txt
open("error_log.txt", "w").close()
asyncio.run(main())
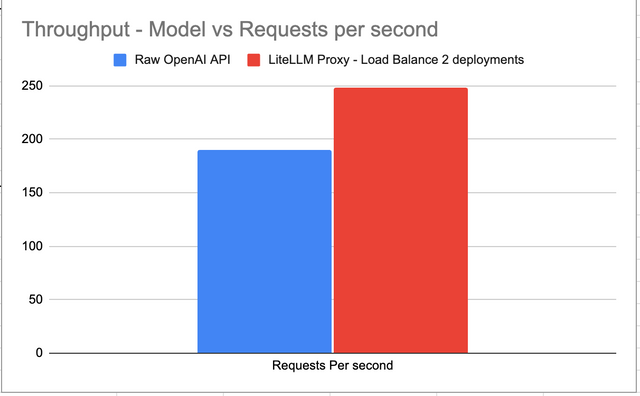
Throughput - 30% Increase
LiteLLM proxy + Load Balancer gives 30% increase in throughput compared to Raw OpenAI API
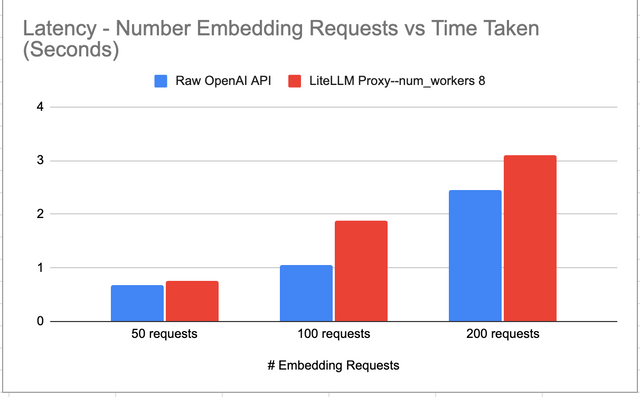
Latency Added - 0.00325 seconds
LiteLLM proxy adds 0.00325 seconds latency as compared to using the Raw OpenAI API
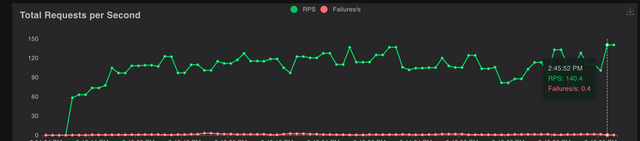
Testing LiteLLM Proxy with Locust
- 1 LiteLLM container can handle ~140 requests/second with 0.4 failures
Load Test LiteLLM SDK vs OpenAI
Here is a script to load test LiteLLM vs OpenAI
from openai import AsyncOpenAI, AsyncAzureOpenAI
import random, uuid
import time, asyncio, litellm
# import logging
# logging.basicConfig(level=logging.DEBUG)
#### LITELLM PROXY ####
litellm_client = AsyncOpenAI(
api_key="sk-1234", # [CHANGE THIS]
base_url="http://0.0.0.0:4000"
)
#### AZURE OPENAI CLIENT ####
client = AsyncAzureOpenAI(
api_key="my-api-key", # [CHANGE THIS]
azure_endpoint="my-api-base", # [CHANGE THIS]
api_version="2023-07-01-preview"
)
#### LITELLM ROUTER ####
model_list = [
{
"model_name": "azure-canada",
"litellm_params": {
"model": "azure/my-azure-deployment-name", # [CHANGE THIS]
"api_key": "my-api-key", # [CHANGE THIS]
"api_base": "my-api-base", # [CHANGE THIS]
"api_version": "2023-07-01-preview"
}
}
]
router = litellm.Router(model_list=model_list)
async def openai_completion():
try:
response = await client.chat.completions.create(
model="gpt-35-turbo",
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
stream=True
)
return response
except Exception as e:
print(e)
return None
async def router_completion():
try:
response = await router.acompletion(
model="azure-canada", # [CHANGE THIS]
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
stream=True
)
return response
except Exception as e:
print(e)
return None
async def proxy_completion_non_streaming():
try:
response = await litellm_client.chat.completions.create(
model="sagemaker-models", # [CHANGE THIS] (if you call it something else on your proxy)
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
)
return response
except Exception as e:
print(e)
return None
async def loadtest_fn():
start = time.time()
n = 500 # Number of concurrent tasks
tasks = [proxy_completion_non_streaming() for _ in range(n)]
chat_completions = await asyncio.gather(*tasks)
successful_completions = [c for c in chat_completions if c is not None]
print(n, time.time() - start, len(successful_completions))
# Run the event loop to execute the async function
asyncio.run(loadtest_fn())